Introduction to turbulence/Stationarity and homogeneity
From CFD-Wiki
(→Spatial integral and Taylor microscales) |
m (Stationarity and homogeneity moved to Introduction to turbulence/Stationarity and homogeneity: Correct book title) |
||
| (6 intermediate revisions not shown) | |||
| Line 1: | Line 1: | ||
| + | {{Introduction to turbulence menu}} | ||
| + | |||
== Processes statistically stationary in time == | == Processes statistically stationary in time == | ||
| Line 7: | Line 9: | ||
An alternative way of looking at ''stationarity'' is to note that ''the statistics of the process are independent of the origin in time''. It is obvious from the above, for example, that if the statistics of a process are time independent, then <math> \left\langle u^{n} \left( t \right) \right\rangle = \left\langle u^{n} \left( t + T \right) \right\rangle </math> , etc., where <math> T </math> is some arbitrary translation of the origin in time. Less obvious, but equally true, is that the product <math> \left\langle u \left( t \right) u \left( t' \right) \right\rangle </math> depends only on time difference <math> t'-t </math> and not on <math> t </math> (or <math> t' </math> ) directly. This consequence of stationarity can be extended to any product moment. For example <math> \left\langle u \left( t \right) v \left( t' \right) \right\rangle </math> can depend only on the time difference <math> t'-t </math>. And <math> \left\langle u \left( t \right) v \left( t' \right) w \left( t'' \right)\right\rangle </math> can depend only on the two time differences <math> t'- t </math> and <math> t'' - t </math> (or <math> t'' - t' </math> ) and not <math> t </math> , <math> t' </math> or <math> t'' </math> directly. | An alternative way of looking at ''stationarity'' is to note that ''the statistics of the process are independent of the origin in time''. It is obvious from the above, for example, that if the statistics of a process are time independent, then <math> \left\langle u^{n} \left( t \right) \right\rangle = \left\langle u^{n} \left( t + T \right) \right\rangle </math> , etc., where <math> T </math> is some arbitrary translation of the origin in time. Less obvious, but equally true, is that the product <math> \left\langle u \left( t \right) u \left( t' \right) \right\rangle </math> depends only on time difference <math> t'-t </math> and not on <math> t </math> (or <math> t' </math> ) directly. This consequence of stationarity can be extended to any product moment. For example <math> \left\langle u \left( t \right) v \left( t' \right) \right\rangle </math> can depend only on the time difference <math> t'-t </math>. And <math> \left\langle u \left( t \right) v \left( t' \right) w \left( t'' \right)\right\rangle </math> can depend only on the two time differences <math> t'- t </math> and <math> t'' - t </math> (or <math> t'' - t' </math> ) and not <math> t </math> , <math> t' </math> or <math> t'' </math> directly. | ||
| - | == | + | == Autocorrelation == |
One of the most useful statistical moments in the study of stationary random processes (and turbulence, in particular) is the '''autocorrelation''' defined as the average of the product of the random variable evaluated at two times, i.e. <math> \left\langle u \left( t \right) u \left( t' \right)\right\rangle </math>. Since the process is assumed stationary, this product can depend only on the time difference <math> \tau = t' - t </math>. Therefore the autocorrelation can be written as: | One of the most useful statistical moments in the study of stationary random processes (and turbulence, in particular) is the '''autocorrelation''' defined as the average of the product of the random variable evaluated at two times, i.e. <math> \left\langle u \left( t \right) u \left( t' \right)\right\rangle </math>. Since the process is assumed stationary, this product can depend only on the time difference <math> \tau = t' - t </math>. Therefore the autocorrelation can be written as: | ||
| Line 47: | Line 49: | ||
</td><td width="5%">(4)</td></tr></table> | </td><td width="5%">(4)</td></tr></table> | ||
| - | == | + | == Autocorrelation coefficient == |
It is convenient to define the ''autocorrelation coefficient'' as: | It is convenient to define the ''autocorrelation coefficient'' as: | ||
| Line 91: | Line 93: | ||
for all values of <math> \tau </math> . | for all values of <math> \tau </math> . | ||
| - | == | + | == Integral scale == |
One of the most useful measures of the length of a time a process is correlated with itself is the integral scale defined by | One of the most useful measures of the length of a time a process is correlated with itself is the integral scale defined by | ||
| Line 103: | Line 105: | ||
It is easy to see why this works by looking at Figure 5.2. In effect we have replaced the area under the correlation coefficient by a rectangle of height unity and width <math> T_{int} </math> . | It is easy to see why this works by looking at Figure 5.2. In effect we have replaced the area under the correlation coefficient by a rectangle of height unity and width <math> T_{int} </math> . | ||
| - | == | + | == Temporal Taylor microscale == |
The autocorrelation can be expanded about the origin in a MacClaurin series; i.e., | The autocorrelation can be expanded about the origin in a MacClaurin series; i.e., | ||
| Line 667: | Line 669: | ||
g \left( r \right) \equiv \frac{\left\langle u_{1} \left( x_{1},x_{2}+r,x_{3} \right) u_{1} \left( x_{1},x_{2},x_{3} \right) \right\rangle}{ \left\langle u^{2}_{1} \right\rangle } = \frac{B_{1,1} \left( 0,r,0 \right)}{ B_{1,1} \left( 0,0,0 \right) } | g \left( r \right) \equiv \frac{\left\langle u_{1} \left( x_{1},x_{2}+r,x_{3} \right) u_{1} \left( x_{1},x_{2},x_{3} \right) \right\rangle}{ \left\langle u^{2}_{1} \right\rangle } = \frac{B_{1,1} \left( 0,r,0 \right)}{ B_{1,1} \left( 0,0,0 \right) } | ||
</math> | </math> | ||
| - | </td><td width="5%">( | + | </td><td width="5%">(73)</td></tr></table> |
| + | |||
| + | It is straightforward to show from the definitions that <math> \lambda_{f} </math> and <math> \lambda_{g} </math> are related to the curvature of the <math> f </math> and <math> g </math> correlation functions at <math> r=0 </math>. Specifically, | ||
| + | |||
| + | <table width="70%"><tr><td> | ||
| + | :<math> | ||
| + | \lambda^{2}_{f}= \frac{2}{d^{2} f / dr^{2} |_{r=0} } | ||
| + | </math> | ||
| + | </td><td width="5%">(74)</td></tr></table> | ||
| + | |||
| + | and | ||
| + | |||
| + | <table width="70%"><tr><td> | ||
| + | :<math> | ||
| + | \lambda^{2}_{g}= \frac{2}{d^{2} g / dr^{2} |_{r=0} } | ||
| + | </math> | ||
| + | </td><td width="5%">(75)</td></tr></table> | ||
| + | |||
| + | Since both <math> f </math> and <math> g </math> are symmetrical functions of <math> r </math>, <math> df/dr </math> and <math> dg/dr </math> must be zero at <math> r=0 </math>. It follows immediately that the leading <math> r </math>-dependent term in the expansions about the origin of both autocorrelations are of parabolic form; i.e., | ||
| + | |||
| + | <table width="70%"><tr><td> | ||
| + | :<math> | ||
| + | f \left( r \right) = 1 - \frac{r^{2}}{\lambda^{2}_{f}} + \cdots | ||
| + | </math> | ||
| + | </td><td width="5%">(76)</td></tr></table> | ||
| + | |||
| + | and | ||
| + | |||
| + | <table width="70%"><tr><td> | ||
| + | :<math> | ||
| + | g \left( r \right) = 1 - \frac{r^{2}}{\lambda^{2}_{g}} + \cdots | ||
| + | </math> | ||
| + | </td><td width="5%">(77)</td></tr></table> | ||
| + | |||
| + | This is illustrated in Figure 5.9 which shows that the Taylor microscales are the intersection with the <math> r </math>-axis of a parabola fitted to the appropriate correlation function at the origin. Fitting a parabola is a common way to determine the Taylor microscale, but to do so you must make sure you resolve accurately to scales much smaller than it (typically an order of magnitude smaller is required). Otherwise you are simply determining the spatial filtering of your probe or numerical algorithm. | ||
| + | |||
| + | |||
| + | {{Turbulence credit wkgeorge}} | ||
| + | |||
| + | {{Chapter navigation|Turbulence kinetic energy|Homogeneous turbulence}} | ||
Latest revision as of 09:19, 25 February 2008
| Nature of turbulence |
| Statistical analysis |
| Reynolds averaged equation |
| Turbulence kinetic energy |
| Stationarity and homogeneity |
| Homogeneous turbulence |
| Free turbulent shear flows |
| Wall bounded turbulent flows |
| Study questions
... template not finished yet! |
Processes statistically stationary in time
Many random processes have the characteristic that their statistical properties do not appear to depend directly on time, even though the random variables themselves are time-dependent. For example, consider the signals shown in Figures 2.2 and 2.5
When the statistical properties of a random process are independent of time, the random process is said to be stationary. For such a process all the moments are time-independent, e.g., 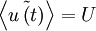 , etc. In fact, the probability density itself is time-independent, as should be obvious from the fact that the moments are time independent.
, etc. In fact, the probability density itself is time-independent, as should be obvious from the fact that the moments are time independent.
An alternative way of looking at stationarity is to note that the statistics of the process are independent of the origin in time. It is obvious from the above, for example, that if the statistics of a process are time independent, then 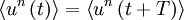 , etc., where
, etc., where 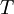 is some arbitrary translation of the origin in time. Less obvious, but equally true, is that the product
is some arbitrary translation of the origin in time. Less obvious, but equally true, is that the product 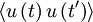 depends only on time difference
depends only on time difference 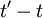 and not on
and not on 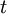 (or
(or 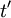 ) directly. This consequence of stationarity can be extended to any product moment. For example
) directly. This consequence of stationarity can be extended to any product moment. For example 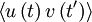 can depend only on the time difference . And
can depend only on the time difference . And 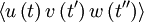 can depend only on the two time differences and
can depend only on the two time differences and 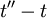 (or
(or 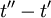 ) and not , or
) and not , or 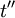 directly.
directly.
Autocorrelation
One of the most useful statistical moments in the study of stationary random processes (and turbulence, in particular) is the autocorrelation defined as the average of the product of the random variable evaluated at two times, i.e. . Since the process is assumed stationary, this product can depend only on the time difference 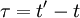 . Therefore the autocorrelation can be written as:
. Therefore the autocorrelation can be written as:
|
| (1) |
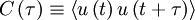
The importance of the autocorrelation lies in the fact that it indicates the "memory" of the process; that is, the time over which is correlated with itself. Contrast the two autocorrelation of deterministic sine wave is simply a cosine as can be easily proven. Note that there is no time beyond which it can be guaranteed to be arbitrarily small since it always "remembers" when it began, and thus always remains correlated with itself. By contrast, a stationary random process like the one illustrated in the figure will eventually lose all correlation and go to zero. In other words it has a "finite memory" and "forgets" how it was. Note that one must be careful to make sure that a correlation really both goes to zero and stays down before drawing conclusions, since even the sine wave was zero at some points. Stationary random process always have two-time correlation functions which eventually go to zero and stay there.
Example 1.
Consider the motion of an automobile responding to the movement of the wheels over a rough surface. In the usual case where the road roughness is randomly distributed, the motion of the car will be a weighted history of the road's roughness with the most recent bumps having the most influence and with distant bumps eventually forgotten. On the other hand, if the car is travelling down a railroad track, the periodic crossing of the railroad ties represents a determenistic input an the motion will remain correlated with itself indefinitely, a very bad thing if the tie crossing rate corresponds to a natural resonance of the suspension system of the vehicle.
Since a random process can never be more than perfectly correlated, it can never achieve a correlation greater than is value at the origin. Thus
|
| (2) |
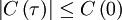
An important consequence of stationarity is that the autocorrelation is symmetric in the time difference . To see this simply shift the origin in time backwards by an amount 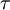 and note that independence of origin implies:
and note that independence of origin implies:
|
| (3) |
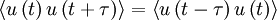
Since the right hand side is simply 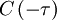 , it follows immediately that:
, it follows immediately that:
|
| (4) |
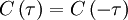
Autocorrelation coefficient
It is convenient to define the autocorrelation coefficient as:
|
| (5) |
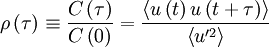
where
|
| (6) |
![\left\langle u^{2} \right\rangle = \left\langle u \left( t \right) u \left( t \right) \right\rangle = C \left( 0 \right) = var \left[ u \right]](/W/images/math/3/2/e/32ed8634122f97dbcde9f2e5a9b03c7e.png)
Since the autocorrelation is symmetric, so is its coefficient, i.e.,
|
| (7) |
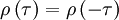
It is also obvious from the fact that the autocorrelation is maximal at the origin that the autocorrelation coefficient must also be maximal there. In fact from the definition it follows that
|
| (8) |
and
|
| (9) |
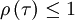
for all values of .
Integral scale
One of the most useful measures of the length of a time a process is correlated with itself is the integral scale defined by
|
| (10) |
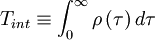
It is easy to see why this works by looking at Figure 5.2. In effect we have replaced the area under the correlation coefficient by a rectangle of height unity and width 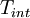 .
.
Temporal Taylor microscale
The autocorrelation can be expanded about the origin in a MacClaurin series; i.e.,
|
| (11) |
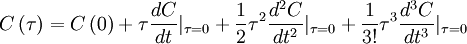
But we know the aoutocorrelation is symmetric in , hence the odd terms in must be identically to zero (i.e., 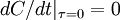 ,
, 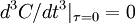 , etc.). Therefore the expansion of the autocorrelation near the origin reduces to:
, etc.). Therefore the expansion of the autocorrelation near the origin reduces to:
|
| (12) |
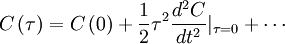
Similary, the autocorrelation coefficient near the origin can be expanded as:
|
| (13) |
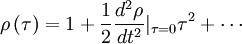
where we have used the fact that  . If we define
. If we define 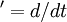 we can write this compactly as:
we can write this compactly as:
|
| (14) |
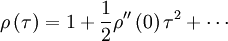
Since 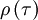 has its maximum at the origin, obviously
has its maximum at the origin, obviously 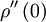 must be negative.
must be negative.
We can use the correlation and its second derivative at the origin to define a special time scale, 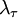 (called the Taylor microscale) by:
(called the Taylor microscale) by:
|
| (15) |
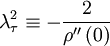
Using this in equation 14 yields the expansion for the correlation coefficient near the origin as:
|
| (16) |
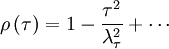
Thus very near the origin the correlation coefficient (and the autocorrelation as well) simply rolls off parabolically; i.e.,
|
| (17) |
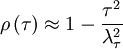
This parabolic curve is shown in Figure 3 as the osculating (or 'kissing') parabola which approaches zero exactly as the autocorrelation coefficient does. The intercept of this osculating parabola with the -axis is the Taylor microscale, .
The Taylor microscale is significant for a number of reasons. First, for many random processes (e.g., Gaussian), the Taylor microscale can be proven to be the average distance between zero-crossing of a random variable in time. This is approximately true for turbulence as well. Thus one can quickly estimate the Taylor microscale by simply observing the zero-crossings using an oscilloscope trace.
The Taylor microscale also has a special relationship to the mean square time derivative of the signal, ![\left\langle \left[ d u / d t \right]^{2} \right\rangle](/W/images/math/f/4/9/f497fde76051c4d53692efc7443bcb41.png) . This is easiest to derive if we consider two stationary random signals at two different times say
. This is easiest to derive if we consider two stationary random signals at two different times say 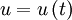 and
and 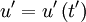 . The derivative of the first signal is
. The derivative of the first signal is 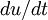 and the second
and the second 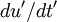 . Now lets multiply these together and rewrite them as:
. Now lets multiply these together and rewrite them as:
|
| (18) |
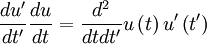
where the right-hand side follows from our assumption that 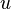 is not a function of nor
is not a function of nor 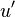 a function of .
a function of .
Now if we average and interchenge the operations of differentiation and averaging we obtain:
|
| (19) |
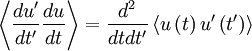
Here comes the first trick: we simply take to be exactly but evaluated at time . So 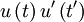 simply becomes
simply becomes 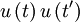 and its average is just the autocorrelation,
and its average is just the autocorrelation, 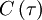 . Thus we are left with:
. Thus we are left with:
|
| (20) |
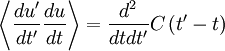
Now we simply need to use the chain-rule. We have already defined . Let's also define 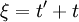 and transform the derivatives involving and to derivatives involving and
and transform the derivatives involving and to derivatives involving and 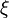 . The result is:
. The result is:
|
| (21) |
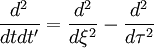
So equation 20 becomes
|
| (22) |
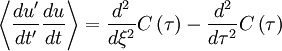
But since 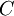 is a function only of , the derivative of it with respect to is identically zero. Thus we are left with:
is a function only of , the derivative of it with respect to is identically zero. Thus we are left with:
|
| (23) |
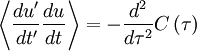
And finally we need the second trick. Let's evaluate both sides at 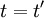 (or
(or 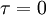 ) to obtain the mean square derivative as:
) to obtain the mean square derivative as:
|
| (24) |
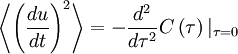
But from our definition of the Taylor microscale and the facts that 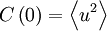 and
and 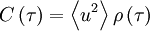 , this is exactly the same as:
, this is exactly the same as:
|
| (25) |
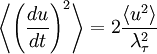
This amasingly simple result is very important in the study of turbulence, especially after we extend it to spatial derivatives.
Time averages of stationary processes
It is common practice in many scientific disciplines to define a time average by integrating the random variable over a fixed time interval, i.e. ,
|
| (26) |
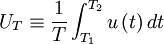
For the stationary random processes we are considering here, we can define 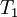 to be the origin in time and simply write:
to be the origin in time and simply write:
|
| (27) |
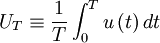
where 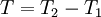 is the integration time.
is the integration time.
Figure 5.4. shows a portion of a stationary random signal over which such an integration might be performed. The ime integral of 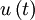 over the integral
over the integral 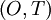 corresponds to the shaded area under the curve. Now since is random and since it formsthe upper boundary of the shadd area, it is clear that the time average,
corresponds to the shaded area under the curve. Now since is random and since it formsthe upper boundary of the shadd area, it is clear that the time average, 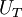 is a lot like the estimator for the mean based on a finite number of independent realization,
is a lot like the estimator for the mean based on a finite number of independent realization, 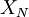 we encountered earlier in section Estimation from a finite number of realizations (see Elements of statistical analysis)
we encountered earlier in section Estimation from a finite number of realizations (see Elements of statistical analysis)
It will be shown in the analysis presented below that if the signal is stationary, the time average defined by equation 27 is an unbiased estimator of the true average 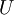 . Moreover, the estimator converges to as the time becomes infinite; i.e., for stationary random processes
. Moreover, the estimator converges to as the time becomes infinite; i.e., for stationary random processes
|
| (28) |
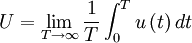
Thus the time and ensemble averages are equivalent in the limit as 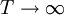 , but only for a stationary random process.
, but only for a stationary random process.
Bias and variability of time estimators
It is easy to show that the estimator, , is unbiased by taking its ensemble average; i.e.,
|
| (29) |
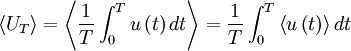
Since the process has been assumed stationary, 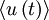 is independent of time. It follows that:
is independent of time. It follows that:
|
| (30) |
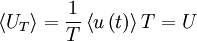
To see whether the etimate improves as increases, the variability of must be examined, exactly as we did for earlier in section Bias and convergence of estimators (see chapter The elements of statistical analysis). To do this we need the variance of given by:
|
| (31) |
![\begin{matrix}
var \left[ U_{T} \right] & = & \left\langle \left[ U_{T} - \left\langle U_{T} \right\rangle \right]^{2} \right\rangle = \left\langle \left[ U_{T} - U \right]^{2} \right\rangle \\
& = & \frac{1}{T^{2}} \left\langle \left\{ \int^{T}_{0} \left[ u \left( t \right) - U \right] \right\}^{2} \right\rangle \\
& = & \frac{1}{T^{2}} \left\langle \int^{T}_{0} \int^{T}_{0} \left[ u \left( t \right) - U \right] \left[ u \left( t' \right) - U \right] dtdt' \right\rangle \\
& = & \frac{1}{T^{2}} \int^{T}_{0} \int^{T}_{0} \left\langle u'\left( t \right) u'\left( t' \right) \right\rangle dtdt' \\
\end{matrix}](/W/images/math/c/2/d/c2d925b6fa6871529cbd0dc983799423.png)
But since the process is assumed stationary 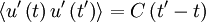 where
where 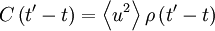 is the correlation coefficient. Therefore the integral can be rewritten as:
is the correlation coefficient. Therefore the integral can be rewritten as:
|
| (33) |
![\begin{matrix}
var \left[ U_{T} \right] & = & \frac{1}{T^{2}} \int^{T}_{0} \int^{T}_{0} C \left( t' - t \right) dtdt' \\
& = & \frac{ \left\langle u^{2} \right\rangle }{ T^{2} } \int^{T}_{0} \int^{T}_{0} \rho \left( t' - t \right) dtdt' \\
\end{matrix}](/W/images/math/2/c/8/2c83678071b76f6d57f97c198c9672a5.png)
Now we need to apply some fancy calculus. If new variables and are defined, the double integral can be transformed to (see Figure 5.5):
|
| (35) |
![var \left[ U_{T} \right] = \frac{var \left[ u \right]}{2 T^{2}} \left[ \int^{T}_{0} d \tau \int^{T-\tau}_{\tau} d \xi \rho \left( \tau \right) + \int^{0}_{-T} d \tau \int^{T+\tau}_{-\tau} d \xi \rho \left( \tau \right) \right]](/W/images/math/c/6/0/c603247b823ab77ca6adb98b06004b20.png)
where the factor of 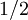 arises from the Jacobian of the transformation. The integrals over
arises from the Jacobian of the transformation. The integrals over 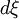 can be evaluated directly to yield:
can be evaluated directly to yield:
|
| (36) |
![var \left[ U_{T} \right] = \frac{var \left[ u \right]}{2 T^{2}} \left\{ \int^{T}_{0} \rho \left( \tau \right) \left[ T - \tau \right] d \tau + \int^{0}_{-T} \rho \left( \tau \right) \left[ T + \tau \right] \right\}](/W/images/math/e/1/d/e1d635325c44519798d9588941681ecb.png)
By noting that the autocorrelation is symmetric, the second integral can be transformed and added to the first to yield at last the result we seek as:
|
| (37) |
![var \left[ U_{T} \right] = \frac{var \left[ u \right]}{T} \int^{T}_{-T} \rho \left( \tau \right) \left[ 1 - \frac{ \left| \tau \right| }{T} \right] d \tau](/W/images/math/0/b/c/0bc5cfe78372c5f14d0042d012db1acc.png)
Now if our averaging time, , is chosen so large that 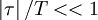 over the range for which is non-zero, the integral reduces:
over the range for which is non-zero, the integral reduces:
|
| (38) |
![\begin{matrix}
var \left[ U_{T} \right] & \approx & \frac{2 var \left[ u \right]}{T} \int^{T}_{0} \rho \left( \tau \right) d \tau \\
& = & \frac{2 T_{int}}{T} var \left[ u \right] \\
\end{matrix}](/W/images/math/c/b/b/cbb0b4ec07726d2909663bcebdb36770.png)
where is the integral scale defined by equation 10. Thus the variability of our estimator is given by:
|
| (39) |
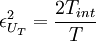
Therefore the estimator does, in fact, converge (in mean square) to the correct result as the averaging time, increases relative to the integral scale, .
There is a direct relationship between equation 39 and equation 52 in chapter The elements of statistical analysis ( section Bias and convergence of estimators) which gave the mean square variability for the ensemble estimate from a finite number of statistically independent realizations, . Obviously the effective number of independent realizations for the finite time estimator is:
|
| (40) |
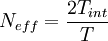
so that the two expressions are equivalent. Thus, in effect, portions of the record separated by two integral scales behave as though they were statistically independent, at least as far as convergence of finite time estimators is concerned.
Thus what is required for convergence is again, many independent pieces of information. This is illustrated in Figure 5.6. That the length of the recordn should be measured in terms of the integral scale should really be no surprise since it is a measure of the rate at which a process forgets its past.
Example
It is desired to mesure the mean velocity in a turbulent flow to within an rms error of 1% (i.e. 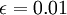 ). The expected fluctuation level of the signal is 25% and integral scale is estimated as 100 ms. What is the required averaging time?
). The expected fluctuation level of the signal is 25% and integral scale is estimated as 100 ms. What is the required averaging time?
From equation 39
|
| (41) |
![\begin{matrix}
T & = & \frac{2T_{int}}{\epsilon^{2}} \frac{var \left[ u \right]}{U^{2}} \\
& = & 2 \times 0.1 \times (0.25)^{2} / (0.01)^{2} = 125 sec \\
\end{matrix}](/W/images/math/a/5/a/a5a486196b7a5475627aa52f1a22defe.png)
Similar considerations apply to any other finite time estimator and equation 55 from chapter Statistical analysis can be applied directly as long as equation 40 is used for the number of independent samples.
It is common common experimental practice to not actually carry out an analog integration. Rather the signal is sampled at fixed intervals in time by digital means and the averages are computed as for an esemble with a finite number of realizations. Regardless of the manner in which the signal is processed, only a finite portion of a stationary time series can be analyzed and the preceding considerations always apply.
It is important to note that data sampled more rapidly than once every two integral scales do not contribute to the convergence of the estimator since they can not be considered independent. If 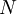 is the actual number of samples acquired and
is the actual number of samples acquired and 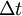 is the time between samples, then the effective number of independent realizations is
is the time between samples, then the effective number of independent realizations is
|
| (42) |
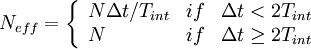
It should be clear that if you sample faster than 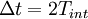 you are processing unnecessary data which does not help your statistics converge.
you are processing unnecessary data which does not help your statistics converge.
You may wonder why one would ever take data faster than absolutely necessary, since it simply it simply fills up your computer memory with lots of statistically redundant data. When we talk about measuring spectra you will learn that for spectral measurements it is necessary to sample much faster to avoid spactral aliasing. Many wrongly infer that they must sample at these higher rates even when measuring just moments. Obviously this is not the case if you are not measuring spectra.
Random fields of space and time
To this point only temporally varying random fields have been discussed. For turbulence however, random fields can be functions of both space and time. For example, the temperature 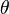 could be a random scalar function of time and position
could be a random scalar function of time and position 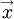 , i.e.,
, i.e.,
|
| (43) |
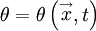
The velocity is another example of a random vector function of position and time, i.e.,
|
| (44) |
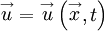
or in tensor notation,
|
| (45) |
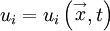
In the general case, the ensemble averages of these quantities are functions of both positon and time; i.e.,
|
| (46) |
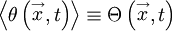
|
| (47) |
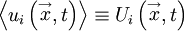
If only stationary random processes are considered, then the averages do not depend on time and are functions of only; i.e.,
|
| (48) |
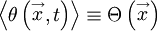
|
| (49) |
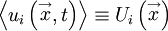
Now the averages may not be position dependent either. For example, if the averages are independent of the origin in position, then the field is said to be homogeneous. Homogenity (the noun corresponding to the adjective homogeneous) is exactly analogous to stationarity except that position is now the variable, and not time.
It is, of course, possible (at least in concept) to have homogeneous fields which are either stationary or non stationary. Since position, unlike time, is a vector quantity it is also possible to have only partial homogeneity. For example, a field can be homogeneous in the 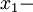 and
and 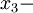 directions, but not in the
directions, but not in the 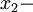 direction so that
direction so that 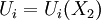 only. In fact, it appears to be dynamically impossible to have flows which are honogeneous in all variables and stationary as well, but the concept is useful, nonetheless.
only. In fact, it appears to be dynamically impossible to have flows which are honogeneous in all variables and stationary as well, but the concept is useful, nonetheless.
Homogeneity will be seen to have powerful consequences for the equations govering the averaged motion, since the spatial derivative of any averaged quantity must be identically zero. Thus even homogeneity in only one direction can considerably simplify the problem. For example, in the Reynolds stress transport equation, the entire turbulence transport is exactly zero if the field is homogeneous.
Multi-point statistics in homogeneous field
The concept of homogeneity can also be extended to multi-point statistics. Consider for example, the correlation between the velocity at one point and that at another as illustrated in Figure 5.7. If the time dependence is suppressed and the field is assumed statistically homogeneous, this correlation is a function only of the separation of the two points, i.e.,
|
| (50) |
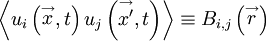
where 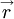 is the separation vector defined by
is the separation vector defined by
|
| (51) |
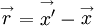
or
|
| (52) |
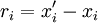
Note that the convention we shall follow for vector quantities is that the first subscript on 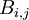 is the component of velocity at the first position, , and the second subscript is the component of velocity at the second,
is the component of velocity at the first position, , and the second subscript is the component of velocity at the second, 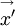 . For scalar quantities we shall simply put a simbol for the quantity to hold the place. For example, we would write the two-point temperature correlation in a homogeneous field by:
. For scalar quantities we shall simply put a simbol for the quantity to hold the place. For example, we would write the two-point temperature correlation in a homogeneous field by:
|
| (53) |
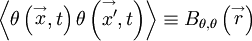
A mixed vector/scalar correlation like the two-point temperature velocity correlation would be written as:
|
| (54) |

On the other hand, if we meant for the temperature to be evaluated at and the velocity at we would have to write:
|
| (55) |

Now most books don't bother with the subscript notation, and simply give each new correlation a new symbol. At first this seems much simpler; and it is as long as you are only dealing with one or two different correlations. But introduce a few more, then read about a half-dozen pages, and you will find you completely forget what they are or how they were put together. It is usually very important to know exactly what you are talking about, so we will use this comma system to help us remember.
It is easy to see that the consideration of vector quantities raises special considerations. For example, the correlation between a scalar function of position at two points is symmetrical in , i.e.,
|
| (56) |
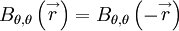
This is easy to show from the definition of 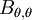 and the fact that the field is homogeneous. Simply shift each of the position vectors by the same amount
and the fact that the field is homogeneous. Simply shift each of the position vectors by the same amount 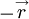 as shown in Figure 5.8 to obtain:
as shown in Figure 5.8 to obtain:
|
| (57) |
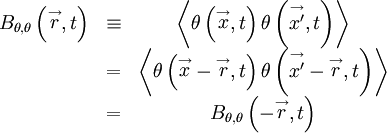
since 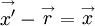 ; i.e., the points are reversed and the separation vector is pointing the opposite way.
; i.e., the points are reversed and the separation vector is pointing the opposite way.
Such is not the case, in general, for vector functions of position. For example, see if you can prove to yourself the following:
|
| (58) |
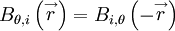
and
|
| (59) |
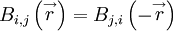
Clearly the latter is symmetrical in the variable only when 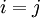 .
.
These properties of the two-point correlation function will be seen to play an important role in determining the interrelations among the different two-point statistical quantities. They will be especially important when we talk about spectral quantities.
Spatial integral and Taylor microscales
Just as for a stationary random process, correlations between spatially varying, but statistically homogeneous, random quantities ultimately go to zero;, i.e., they become uncorrelated as their locations become widely separated. Because position (o relative position) is a vector quantity, however, the correlation the carrelation may die off at different rates in different directions. Thus direction must be an important part of the definitions of the integral scales and microscales.
Consider for example the one-dimensional spatial correlation which is obtained by measuring the correlation between the temperature at two points along a line in the x-direction, say,
|
| (60) |
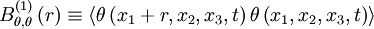
The superscript "(1)" denotes "the coordinate direction in which the separation occurs". This distinguishes it from the vector separation of above. Also, note that the correlation at zero separationis just the variance; i.e.,
|
| (61) |
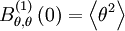
The integral scale in the  -direction can be defined as:
-direction can be defined as:
|
| (62) |
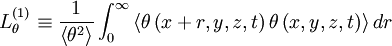
It is clear that there are at least two more integral scales which could be defined by considering separations in the y and z directions. Thus
|
| (63) |
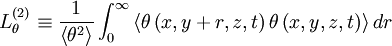
and
|
| (64) |
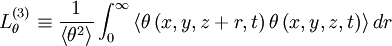
In fact, an integral scale could be defined for any direction simply by choosing the components of the separation vector . This situation is even more complicated when correlations of vector quantities are considered. For example, consider the correlation of the velocity vectors at two points, 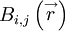 . Clearly is not a single correlation, but rather nine separate correlations:
. Clearly is not a single correlation, but rather nine separate correlations: 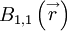 ,
, 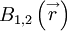 ,
, 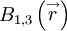 ,
, 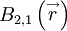 ,
, 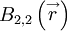 , etc. For each of these an integral scale can be defined once a direction for the separation vector is chosen. For example, the integral scales associated with
, etc. For each of these an integral scale can be defined once a direction for the separation vector is chosen. For example, the integral scales associated with 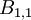 for the principal directions are
for the principal directions are
|
| (65) |
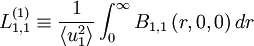
|
| (66) |
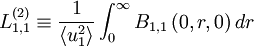
|
| (67) |
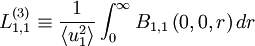
Similar integral scales can be defined for the other componentsof the correlation tensor. Two of particular importance in the development of the turbulence theory are:
|
| (68) |
|
| (69) |
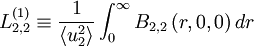
In general, each of these integral scales will be different, unless restrictions beyond simple homogeneity are placed on the process (e.g., like isotropy discussed below). Thus, it is important to specify precisely which integral scale is being referred to; i.e., which components of the vector quantities are being used and in which direction the integration is being performed.
Similar considerations apply to the Taylor microscales, regardless of whether they are being determined from the correlations at small separations, or from the mean square fluctuating gradients. The two most commonly used Taylor microscales are often referred to as 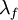 and
and 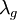 and are defined by
and are defined by
|
| (70) |
![\lambda^{2}_{f} \equiv 2 \frac{ \left\langle u^{2}_{1} \right\rangle }{ \left\langle \left[ \partial u_{1} / \partial x_{1} \right]^{2} \right\rangle }](/W/images/math/5/7/5/5755ab594ab335157ac4c8fa18e7eb0b.png)
and
|
| (71) |
![\lambda^{2}_{g} \equiv 2 \frac{ \left\langle u^{2}_{1} \right\rangle }{ \left\langle \left[ \partial u_{1} / \partial x_{2} \right]^{2} \right\rangle }](/W/images/math/2/6/f/26f98a7e923c5dc88d18c053b00e7b6e.png)
The subscripts f and g refer to the autocorrelation coefficients defined by:
|
| (72) |
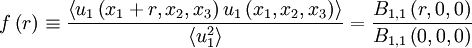
and
|
| (73) |
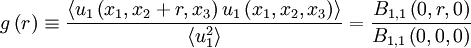
It is straightforward to show from the definitions that and are related to the curvature of the 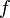 and
and 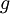 correlation functions at
correlation functions at 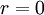 . Specifically,
. Specifically,
|
| (74) |
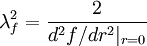
and
|
| (75) |
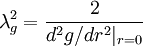
Since both and are symmetrical functions of  ,
,  and
and 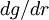 must be zero at . It follows immediately that the leading -dependent term in the expansions about the origin of both autocorrelations are of parabolic form; i.e.,
must be zero at . It follows immediately that the leading -dependent term in the expansions about the origin of both autocorrelations are of parabolic form; i.e.,
|
| (76) |
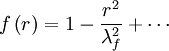
and
|
| (77) |
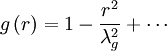
This is illustrated in Figure 5.9 which shows that the Taylor microscales are the intersection with the -axis of a parabola fitted to the appropriate correlation function at the origin. Fitting a parabola is a common way to determine the Taylor microscale, but to do so you must make sure you resolve accurately to scales much smaller than it (typically an order of magnitude smaller is required). Otherwise you are simply determining the spatial filtering of your probe or numerical algorithm.
Credits
This text was based on "Lectures in Turbulence for the 21st Century" by Professor William K. George, Professor of Turbulence, Chalmers University of Technology, Gothenburg, Sweden.