Introduction to turbulence/Statistical analysis/Estimation from a finite number of realizations
From CFD-Wiki
(→Bias and convergence of estimators) |
Ayyoubzadeh (Talk | contribs) (→Bias and convergence of estimators) |
||
| (19 intermediate revisions not shown) | |||
| Line 1: | Line 1: | ||
| + | {{Introduction to turbulence menu}} | ||
== Estimators for averaged quantities == | == Estimators for averaged quantities == | ||
| Line 7: | Line 8: | ||
The second question is | The second question is | ||
| - | * Does the difference between the and that of the true mean decrease as the number of realizations increases? Or in other words, does the estimator ''converge'' in a statistical sense (or converge in probability). Figure 2.9 illustrates the problems which can arise. | + | * Does the difference between the and that of the true mean decrease as the number of realizations increases? Or in other words, does the estimator ''converge'' in a statistical sense (or converge in probability). <font color="orange">Figure 2.9</font> illustrates the problems which can arise. |
== Bias and convergence of estimators == | == Bias and convergence of estimators == | ||
A procedure for answering these questions will be illustrated by considerind a simple '''estimator''' for the mean, the arithmetic mean considered above, <math>X_{N}</math>. For <math>N</math> independent realizations <math>x_{n}, n=1,2,...,N</math> where <math>N</math> is finite, <math>X_{N}</math> is given by: | A procedure for answering these questions will be illustrated by considerind a simple '''estimator''' for the mean, the arithmetic mean considered above, <math>X_{N}</math>. For <math>N</math> independent realizations <math>x_{n}, n=1,2,...,N</math> where <math>N</math> is finite, <math>X_{N}</math> is given by: | ||
| + | |||
| + | :<math>X_{N}=\frac{1}{N}\sum^{N}_{n=1} x_{n}</math> | ||
| + | |||
| + | <font color="orange" size="3">Figure 2.9 not uploaded yet</font> | ||
| + | |||
| + | Now, as we observed in our simple coin-flipping experiment, since the <math>x_{n}</math> are random, so must be the value of the estimator <math>X_{N}</math>. For the estimator to be ''unbiased'', the mean value of <math>X_{N}</math> must be true ensemble mean, <math>X</math>, i.e. | ||
| + | |||
| + | :<math>\lim_{N\rightarrow\infty} X_{N} = X</math> | ||
| + | |||
| + | It is easy to see that since the operations of averaging adding commute, | ||
| - | |||
:<math> | :<math> | ||
| - | X_{N}=\frac{1}{N}\sum^{N}_{n=1} x_{n} | + | \begin{matrix} |
| + | \left\langle X_{N} \right\rangle & = & \left\langle \frac{1}{N} \sum^{N}_{n=1} x_{n} \right\rangle \\ | ||
| + | & = & \frac{1}{N} \sum^{N}_{n=1} \left\langle x_{n} \right\rangle \\ | ||
| + | & = & \frac{1}{N} NX = X \\ | ||
| + | \end{matrix} | ||
</math> | </math> | ||
| - | </ | + | |
| + | (Note that the expected value of each <math>x_{n}</math> is just <math>X</math> since the <math>x_{n}</math> are assumed identically distributed). Thus <math>x_{N}</math> is, in fact, an ''unbiased estimator for the mean''. | ||
| + | |||
| + | The question of ''convergence'' of the estimator can be addressed by defining the square of '''variability of the estimator''', say <math>\epsilon^{2}_{X_{N}}</math>, to be: | ||
| + | |||
| + | :<math> | ||
| + | \epsilon^{2}_{X_{N}}\equiv \frac{var \left\{ X_{N} \right\} }{X^{2}} = \frac{\left\langle \left( X_{N}- X \right)^{2} \right\rangle }{X^{2}} | ||
| + | </math> | ||
| + | |||
| + | Now we want to examine what happens to <math>\epsilon_{X_{N}}</math> as the number of realizations increases. For the estimator to converge it is clear that <math>\epsilon_{x}</math> should decrease as the number of sample increases. Obviously, we need to examine the variance of <math>X_{N}</math> first. It is given by: | ||
| + | |||
| + | :<math> | ||
| + | \begin{matrix} | ||
| + | var \left\{ X_{N} \right\} & = & \left\langle X_{N} - X^{2} \right\rangle \\ | ||
| + | & = & \left\langle \left[ \lim_{N\rightarrow\infty} \frac{1}{N} \sum^{N}_{n=1} \left( x_{n} - X \right) \right]^{2} \right\rangle - X^{2}\\ | ||
| + | \end{matrix} | ||
| + | </math> | ||
| + | |||
| + | since <math>\left\langle X_{N} \right\rangle = X</math> from the equation for <math>\langle X_{N} \rangle</math> above. Using the fact that operations of averaging and summation commute, the squared summation can be expanded as follows: | ||
| + | |||
| + | :<math> | ||
| + | \begin{matrix} | ||
| + | \left\langle \left[ \lim_{N\rightarrow\infty} \sum^{N}_{n=1} \left( x_{n} - X \right) \right]^{2} \right\rangle & = & \lim_{N\rightarrow\infty}\frac{1}{N^{2}} \sum^{N}_{n=1} \sum^{N}_{m=1} \left\langle \left( x_{n} - X \right) \left( x_{m} - X \right) \right\rangle \\ | ||
| + | & = & \lim_{N\rightarrow\infty}\frac{1}{N^{2}}\sum^{N}_{n=1}\left\langle \left( x_{n} - X \right)^{2} \right\rangle \\ | ||
| + | & = & \frac{1}{N} var \left\{ x \right\} \\ | ||
| + | \end{matrix} | ||
| + | </math> | ||
| + | |||
| + | where the next to last step follows from the fact that the <math>x_{n}</math> are assumed to be statistically independent samples (and hence uncorrelated), and the last step from the definition of the variance. It follows immediately by substitution into the equation for <math>\epsilon^{2}_{X_{N}}</math> above that the square of the variability of the estimator, <math>X_{N}</math>, is given by: | ||
| + | |||
| + | :<math> | ||
| + | \begin{matrix} | ||
| + | \epsilon^{2}_{X_{N}}& =& \frac{1}{N}\frac{var\left\{x\right\}}{X^{2}} \\ | ||
| + | & = & \frac{1}{N} \left[ \frac{\sigma_{x}}{X} \right]^{2} \\ | ||
| + | \end{matrix} | ||
| + | </math> | ||
| + | |||
| + | Thus ''the variability of the estimator depends inversely on the number of independent realizations, <math>N</math>, and linearly on the relative fluctuation level of the random variable itself <math>\sigma_{x}/ X</math>''. Obviously if the relative fluctuation level is zero (either because there the quantity being measured is constant and there are no measurement errors), then a single measurement will suffice. On the other hand, as soon as there is any fluctuation in the <math>x</math> itself, the greater the fluctuation ( relative to the mean of <math>x</math>, <math>\left\langle x \right\rangle = X</math> ), then the more independent samples it will take to achieve a specified accuracy. | ||
| + | |||
| + | '''Example:''' In a given ensemble the relative fluctuation level is 12% (i.e. <math>\sigma_{x}/ X = 0.12</math>). What is the fewest number of independent samples that must be acquired to measure the mean value to within 1%? | ||
| + | |||
| + | '''Answer'''Using the equation for <math>\epsilon^{2}_{X_{N}}</math> above, and taking <math>\epsilon_{X_{N}}=0.01</math>, it follows that: | ||
| + | |||
| + | :<math> | ||
| + | \left(0.01 \right)^{2} = \frac{1}{N}\left(0.12 \right)^{2} | ||
| + | </math> | ||
| + | |||
| + | or <math>N \geq 144</math>. | ||
| + | |||
| + | {{Turbulence credit wkgeorge}} | ||
| + | |||
| + | {{Chapter navigation|Multivariate random variables|Generalization to the estimator of any quantity}} | ||
Latest revision as of 16:42, 31 August 2007
Estimators for averaged quantities
Since there can never an infinite number of realizations from which ensemble averages (and probability densities) can be computed, it is essential to ask: How many realizations are enough? The answer to this question must be sought by looking at the statistical properties of estimators based on a finite number of realization. There are two questions which must be answered. The first one is:
- Is the expected value (or mean value) of the estimator equal to the true ensemble mean? Or in other words, is yje estimator unbiased?
The second question is
- Does the difference between the and that of the true mean decrease as the number of realizations increases? Or in other words, does the estimator converge in a statistical sense (or converge in probability). Figure 2.9 illustrates the problems which can arise.
Bias and convergence of estimators
A procedure for answering these questions will be illustrated by considerind a simple estimator for the mean, the arithmetic mean considered above, 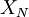 . For
. For 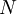 independent realizations
independent realizations 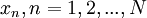 where is finite, is given by:
where is finite, is given by:
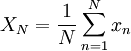
Figure 2.9 not uploaded yet
Now, as we observed in our simple coin-flipping experiment, since the 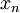 are random, so must be the value of the estimator . For the estimator to be unbiased, the mean value of must be true ensemble mean,
are random, so must be the value of the estimator . For the estimator to be unbiased, the mean value of must be true ensemble mean, 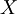 , i.e.
, i.e.
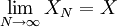
It is easy to see that since the operations of averaging adding commute,
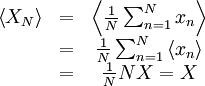
(Note that the expected value of each is just since the are assumed identically distributed). Thus 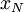 is, in fact, an unbiased estimator for the mean.
is, in fact, an unbiased estimator for the mean.
The question of convergence of the estimator can be addressed by defining the square of variability of the estimator, say 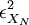 , to be:
, to be:
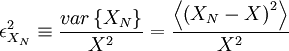
Now we want to examine what happens to 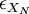 as the number of realizations increases. For the estimator to converge it is clear that
as the number of realizations increases. For the estimator to converge it is clear that 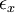 should decrease as the number of sample increases. Obviously, we need to examine the variance of first. It is given by:
should decrease as the number of sample increases. Obviously, we need to examine the variance of first. It is given by:
![\begin{matrix}
var \left\{ X_{N} \right\} & = & \left\langle X_{N} - X^{2} \right\rangle \\
& = & \left\langle \left[ \lim_{N\rightarrow\infty} \frac{1}{N} \sum^{N}_{n=1} \left( x_{n} - X \right) \right]^{2} \right\rangle - X^{2}\\
\end{matrix}](/W/images/math/4/2/a/42a377d205dfa9f0689df6d6bac1a092.png)
since 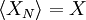 from the equation for
from the equation for 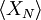 above. Using the fact that operations of averaging and summation commute, the squared summation can be expanded as follows:
above. Using the fact that operations of averaging and summation commute, the squared summation can be expanded as follows:
![\begin{matrix}
\left\langle \left[ \lim_{N\rightarrow\infty} \sum^{N}_{n=1} \left( x_{n} - X \right) \right]^{2} \right\rangle & = & \lim_{N\rightarrow\infty}\frac{1}{N^{2}} \sum^{N}_{n=1} \sum^{N}_{m=1} \left\langle \left( x_{n} - X \right) \left( x_{m} - X \right) \right\rangle \\
& = & \lim_{N\rightarrow\infty}\frac{1}{N^{2}}\sum^{N}_{n=1}\left\langle \left( x_{n} - X \right)^{2} \right\rangle \\
& = & \frac{1}{N} var \left\{ x \right\} \\
\end{matrix}](/W/images/math/a/0/9/a096bbb794633b599445da44489f9cb6.png)
where the next to last step follows from the fact that the are assumed to be statistically independent samples (and hence uncorrelated), and the last step from the definition of the variance. It follows immediately by substitution into the equation for above that the square of the variability of the estimator, , is given by:
![\begin{matrix}
\epsilon^{2}_{X_{N}}& =& \frac{1}{N}\frac{var\left\{x\right\}}{X^{2}} \\
& = & \frac{1}{N} \left[ \frac{\sigma_{x}}{X} \right]^{2} \\
\end{matrix}](/W/images/math/5/a/f/5af293e636864266f2d192289618d56e.png)
Thus the variability of the estimator depends inversely on the number of independent realizations, , and linearly on the relative fluctuation level of the random variable itself 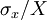 . Obviously if the relative fluctuation level is zero (either because there the quantity being measured is constant and there are no measurement errors), then a single measurement will suffice. On the other hand, as soon as there is any fluctuation in the
. Obviously if the relative fluctuation level is zero (either because there the quantity being measured is constant and there are no measurement errors), then a single measurement will suffice. On the other hand, as soon as there is any fluctuation in the 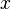 itself, the greater the fluctuation ( relative to the mean of ,
itself, the greater the fluctuation ( relative to the mean of , 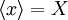 ), then the more independent samples it will take to achieve a specified accuracy.
), then the more independent samples it will take to achieve a specified accuracy.
Example: In a given ensemble the relative fluctuation level is 12% (i.e. 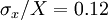 ). What is the fewest number of independent samples that must be acquired to measure the mean value to within 1%?
). What is the fewest number of independent samples that must be acquired to measure the mean value to within 1%?
AnswerUsing the equation for above, and taking 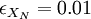 , it follows that:
, it follows that:
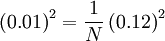
or 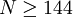 .
.
Credits
This text was based on "Lectures in Turbulence for the 21st Century" by Professor William K. George, Professor of Turbulence, Chalmers University of Technology, Gothenburg, Sweden.