Two equation turbulence models
From CFD-Wiki
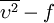 model
model
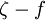 model
model
Two equation turbulence models are one of the most common type of turbulence models. Models like the k-epsilon model and the k-omega model have become industry standard models and are commonly used for most types of engineering problems. Two equation turbulence models are also very much still an active area of research and new refined two-equation models are still being developed.
By definition, two equation models include two extra transport equations to represent the turbulent properties of the flow. This allows a two equation model to account for history effects like convection and diffusion of turbulent energy.
Most often one of the transported variables is the turbulent kinetic energy, 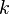 . The second transported variable varies depending on what type of two-equation model it is. Common choices are the turbulent dissipation,
. The second transported variable varies depending on what type of two-equation model it is. Common choices are the turbulent dissipation,  , or the specific dissipation,
, or the specific dissipation, 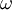 . The second variable can be thought of as the variable that determines the scale of the turbulence (length-scale or time-scale), whereas the first variable, , determines the energy in the turbulence.
. The second variable can be thought of as the variable that determines the scale of the turbulence (length-scale or time-scale), whereas the first variable, , determines the energy in the turbulence.
Boussinesq eddy viscosity assumption
The basis for all two equation models is the Boussinesq eddy viscosity assumption, which postulates that the Reynolds stress tensor, 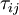 , is proportional to the mean strain rate tensor,
, is proportional to the mean strain rate tensor, 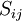 , and can be written in the following way:
, and can be written in the following way:
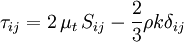
Where 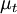 is a scalar property called the eddy viscosity which is normally computed from the two transported variables. The last term is included for modelling incompressible flow to ensure that the definition of turbulence kinetic energy is obeyed:
is a scalar property called the eddy viscosity which is normally computed from the two transported variables. The last term is included for modelling incompressible flow to ensure that the definition of turbulence kinetic energy is obeyed:
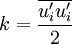
The same equation can be written more explicitly as:
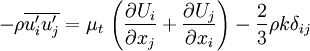
The Boussinesq assumption is both the strength and the weakness of two equation models. This assumption is a huge simplification which allows one to think of the effect of turbulence on the mean flow in the same way as molecular viscosity affects a laminar flow. The assumption also makes it possible to introduce intuitive scalar turbulence variables like the turbulent energy and dissipation and to relate these variables to even more intuitive variables like turbulence intensity and turbulence length scale.
The weakness of the Boussinesq assumption is that it is not in general valid. There is nothing which says that the Reynolds stress tensor must be proportional to the strain rate tensor. It is true in simple flows like straight boundary layers and wakes, but in complex flows, like flows with strong curvature, or strongly accelerated or decellerated flows the Boussinesq assumption is simply not valid. This give two equation models inherent problems to predict strongly rotating flows and other flows where curvature effects are significant. Two equation models also often have problems to predict strongly decellerated flows like stagnation flows.
Near-wall treatments
The structure of turbulent boundary layer exhibits large, compared with the flow in the core region, gradients of velocity and quantities characterising turbulence. In a collocated grid these gradients will be approximated using discretisation procedures which are not suitable for such high variation since they usually assume linear interpolation of values between cell centres.
Moreover, the additional quantities appearing in two-equation models require specification of their own boundary conditions that on purely physical grounds cannot be specified a priori.
This situation gave rise to a plethora of near-wall treatments. Generally speaking two approaches can be distinguished:
- Low Reynolds number treatment (LRN) integrates every equation up to the viscous sublayer and therefore the first computational computational cell must have its centroid in viscous sublayer. This results in very fine meshes close to the wall. Additionally, for some models additional treatment (damping functions) of equations is required to guarantee asymptotic consistency with the turbulent boundary layer behaviour. This often makes the equations stiff and further increases computation time.
- High Reynolds number treatment (HRN) also known as wall functions approach relies on log-law velocity profile and therefore the first computational cell must have its centroid in the log-layer. Use of HRN enhances convergence rate and often numerical stability.

Interestingly, none of the current approaches can deal with buffer layer i.e. the layer in which both viscous and Reynolds stresses are significant. The first computational cell should be either in viscous sublayer or in log-layer -- not in-between. Automatic wall treatments, available in some codes, are an \textit{ad hoc} solution but the blending techniques employed there are usually arbitrary and though they can achieve the switching between HRN and LRN treatments they cannot be regarded as the correct representation of the buffer layer.