General CFD FAQ
From CFD-Wiki
| (13 intermediate revisions not shown) | |||
| Line 1: | Line 1: | ||
This FAQ is empty. This is just a suggestion on how to structure it. Please feel free to add questions and answers here! | This FAQ is empty. This is just a suggestion on how to structure it. Please feel free to add questions and answers here! | ||
== Physics == | == Physics == | ||
| + | === What is the Reynolds decomposition? === | ||
| + | The Reynolds decomposition is used to separate the scales in a turbulent flow and resolve the velocity field (or any other scalar field) as the sum of an average component and a fluctuating component. The time average of the fluctuating field is identically zero. | ||
| + | |||
=== What is the difference between the Reynolds decomposition and LES filtering? === | === What is the difference between the Reynolds decomposition and LES filtering? === | ||
The Reynolds decomposition separates the velocity field into an average component and a fluctuating component. '''The time average of the fluctuating component is identically zero'''. In LES, a filtering operation is performed to decompose the velocity field into a ''filtered'' velocity field and a ''filtered residual'' field. The crucial difference between both methods is | The Reynolds decomposition separates the velocity field into an average component and a fluctuating component. '''The time average of the fluctuating component is identically zero'''. In LES, a filtering operation is performed to decompose the velocity field into a ''filtered'' velocity field and a ''filtered residual'' field. The crucial difference between both methods is | ||
*The filtered velocity field is a '''random variable''' while the average field (Reynolds) is not | *The filtered velocity field is a '''random variable''' while the average field (Reynolds) is not | ||
*The time average of the residual field is generally '''nonzero''' while it is identically zero for fluctuating component in the Reynolds decomposition. | *The time average of the residual field is generally '''nonzero''' while it is identically zero for fluctuating component in the Reynolds decomposition. | ||
| + | |||
| + | === How do I calculate <math>y^+</math> (y plus)? === | ||
| + | In order to calculate <math>y^+</math>, you need to use the definition | ||
| + | :<math>y^+ = \frac{yu_*}{\nu}</math> | ||
| + | where <math>y</math> is a wall distance, <math>u_*</math> is the [[friction velocity]], and <math>\nu</math> is the [[kinematic viscosity]]. Note that this cannot be done unless you have a value for <math>u_*</math>. For more information, see the article on [[Dimensionless wall distance (y plus)]] and the articles linked to there. | ||
| + | |||
== Numerics == | == Numerics == | ||
=== What is the difference between FEM, FVM and FDM? === | === What is the difference between FEM, FVM and FDM? === | ||
| - | + | ||
| + | A finite difference method (FDM) discretization is based upon the differential form of the PDE to be solved. Each derivative is replaced with an approximate difference formula (that can generally be derived from a Taylor series expansion). The computational domain is usually divided into hexahedral cells (the grid), and the solution will be obtained at each nodal point. The FDM is easiest to understand when the physical grid is Cartesian, but through the use of curvilinear transforms the method can be extended to domains that are not easily represented by brick-shaped elements. The discretization results in a system of equation of the variable at nodal points, and once a solution is found, then we have a discrete representation of the solution. | ||
| + | |||
| + | A finite volume method (FVM) discretization is based upon an integral form of the PDE to be solved (e.g. conservation of mass, momentum, or energy). The PDE is written in a form which can be solved for a given finite volume (or cell). The computational domain is discretized into finite volumes and then for every volume the governing equations are solved. The resulting system of equations usually involves fluxes of the conserved variable, and thus the calculation of fluxes is very important in FVM. The basic advantage of this method over FDM is it does not require the use of structured grids, and the effort to convert the given mesh in to structured numerical grid internally is completely avoided. As with FDM, the resulting approximate solution is a discrete, but the variables are typically placed at cell centers rather than at nodal points. This is not always true, as there are also face-centered finite volume methods. In any case, the values of field variables at non-storage locations (e.g. vertices) are obtained using interpolation. | ||
| + | |||
| + | A finite element method (FEM) discretization is based upon a piecewise representation of the solution in terms of specified basis functions. The computational domain is divided up into smaller domains (finite elements) and the solution in each element is constructed from the basis functions. The actual equations that are solved are typically obtained by restating the conservation equation in weak form: the field variables are written in terms of the basis functions, the equation is multiplied by appropriate test functions, and then integrated over an element. Since the FEM solution is in terms of specific basis functions, a great deal more is known about the solution than for either FDM or FVM. This can be a double-edged sword, as the choice of basis functions is very important and boundary conditions may be more difficult to formulate. Again, a system of equations is obtained (usually for nodal values) that must be solved to obtain a solution. | ||
| + | |||
| + | Comparison of the three methods is difficult, primarily due to the many variations of all three methods. FVM and FDM provide discrete solutions, while FEM provides a continuous (up to a point) solution. FVM and FDM are generally considered easier to program than FEM, but opinions vary on this point. FVM are generally expected to provide better conservation properties, but opinions vary on this point also. If you are trying to decide which method to use, then the best path is probably found by consulting the literature in the specific problem area. | ||
| + | |||
| + | === How do I count the number of floating point operations in an algorithm?=== | ||
| + | First, write down your algorithm as pseudocode. Then simply count the number of arithmetic operations that the algorithm is performing (per iteration if the algorithm loops). All operations (addition, subtraction, multiplication, and division) are usually counted as the same, i.e. '''1 flop'''. This is not exactly true, since multiplication includes several additions and division includes several multiplications when actually executed by a computer. However, we are looking for an estimate here, so it is reasonable to assume that on average, all operations count in the same manner. | ||
| + | |||
| + | Here is an example (just for illustration):<br> | ||
| + | : for i = 0 to P <br> | ||
| + | :: for n = 1 to N (number of elements in array) <br> | ||
| + | ::: B(n) = a(n)*a(n-1) - 2*c(n) + 3 <br> | ||
| + | :: next n <br> | ||
| + | : next i <br> | ||
| + | |||
| + | For each '''n''' there are 2 multiplications, 1 subtraction, and 1 addition resulting in '''4''' operations. This loop is executed '''N''' times, so there are '''4N''' operations. This is the the order of the algorithm. In this example, its is O(4N) or simply O(N) (constants do not count). <br> | ||
| + | For all iterations, there are 4N(P+1) operations. (remember, when starting the loop from 0 to P, there are P+1 steps). | ||
| + | |||
| + | == Codes and Coding == | ||
| + | === Which code should I use? === | ||
| + | This question is asked frequently (in one form or another) in the CFD-Online Forums, and there is no easy answer. There are many commercial and noncommercial codes out there, so researching the applicability of various codes is probably worth the effort. Links to lists of CFD codes are available in the [http://www.cfd-online.com/Links/soft.html#cfd CFD-Online Resources list]. | ||
| + | |||
| + | === I'm writing my own code. Which programming language should I use? === | ||
| + | This question, like the previous question, is common and not easy to answer (at least without igniting long discussions - search in the Main Forum archive for examples). Traditionally, the language of choice was Fortran, but C++ and other more recently developed languages are becoming more common. Criticisms of non-Fortran languages usually are based upon performance of the end-result executable, but this sort of criticism has less power as computers become faster. | ||
| + | |||
| + | |||
| + | == Meshing == | ||
| + | === What are the advantages/disadvantages of structural and unstructured Mesh? === | ||
| + | |||
| + | |||
| + | === What are the type of Mesh used for Boundary layer? === | ||
| + | |||
| + | |||
[[Category: FAQ's]] | [[Category: FAQ's]] | ||
{{Stub}} | {{Stub}} | ||
Revision as of 09:20, 9 June 2008
This FAQ is empty. This is just a suggestion on how to structure it. Please feel free to add questions and answers here!
Contents |
Physics
What is the Reynolds decomposition?
The Reynolds decomposition is used to separate the scales in a turbulent flow and resolve the velocity field (or any other scalar field) as the sum of an average component and a fluctuating component. The time average of the fluctuating field is identically zero.
What is the difference between the Reynolds decomposition and LES filtering?
The Reynolds decomposition separates the velocity field into an average component and a fluctuating component. The time average of the fluctuating component is identically zero. In LES, a filtering operation is performed to decompose the velocity field into a filtered velocity field and a filtered residual field. The crucial difference between both methods is
- The filtered velocity field is a random variable while the average field (Reynolds) is not
- The time average of the residual field is generally nonzero while it is identically zero for fluctuating component in the Reynolds decomposition.
How do I calculate 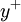 (y plus)?
(y plus)?
In order to calculate , you need to use the definition
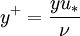
where 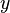 is a wall distance,
is a wall distance, 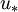 is the friction velocity, and
is the friction velocity, and 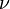 is the kinematic viscosity. Note that this cannot be done unless you have a value for . For more information, see the article on Dimensionless wall distance (y plus) and the articles linked to there.
is the kinematic viscosity. Note that this cannot be done unless you have a value for . For more information, see the article on Dimensionless wall distance (y plus) and the articles linked to there.
Numerics
What is the difference between FEM, FVM and FDM?
A finite difference method (FDM) discretization is based upon the differential form of the PDE to be solved. Each derivative is replaced with an approximate difference formula (that can generally be derived from a Taylor series expansion). The computational domain is usually divided into hexahedral cells (the grid), and the solution will be obtained at each nodal point. The FDM is easiest to understand when the physical grid is Cartesian, but through the use of curvilinear transforms the method can be extended to domains that are not easily represented by brick-shaped elements. The discretization results in a system of equation of the variable at nodal points, and once a solution is found, then we have a discrete representation of the solution.
A finite volume method (FVM) discretization is based upon an integral form of the PDE to be solved (e.g. conservation of mass, momentum, or energy). The PDE is written in a form which can be solved for a given finite volume (or cell). The computational domain is discretized into finite volumes and then for every volume the governing equations are solved. The resulting system of equations usually involves fluxes of the conserved variable, and thus the calculation of fluxes is very important in FVM. The basic advantage of this method over FDM is it does not require the use of structured grids, and the effort to convert the given mesh in to structured numerical grid internally is completely avoided. As with FDM, the resulting approximate solution is a discrete, but the variables are typically placed at cell centers rather than at nodal points. This is not always true, as there are also face-centered finite volume methods. In any case, the values of field variables at non-storage locations (e.g. vertices) are obtained using interpolation.
A finite element method (FEM) discretization is based upon a piecewise representation of the solution in terms of specified basis functions. The computational domain is divided up into smaller domains (finite elements) and the solution in each element is constructed from the basis functions. The actual equations that are solved are typically obtained by restating the conservation equation in weak form: the field variables are written in terms of the basis functions, the equation is multiplied by appropriate test functions, and then integrated over an element. Since the FEM solution is in terms of specific basis functions, a great deal more is known about the solution than for either FDM or FVM. This can be a double-edged sword, as the choice of basis functions is very important and boundary conditions may be more difficult to formulate. Again, a system of equations is obtained (usually for nodal values) that must be solved to obtain a solution.
Comparison of the three methods is difficult, primarily due to the many variations of all three methods. FVM and FDM provide discrete solutions, while FEM provides a continuous (up to a point) solution. FVM and FDM are generally considered easier to program than FEM, but opinions vary on this point. FVM are generally expected to provide better conservation properties, but opinions vary on this point also. If you are trying to decide which method to use, then the best path is probably found by consulting the literature in the specific problem area.
How do I count the number of floating point operations in an algorithm?
First, write down your algorithm as pseudocode. Then simply count the number of arithmetic operations that the algorithm is performing (per iteration if the algorithm loops). All operations (addition, subtraction, multiplication, and division) are usually counted as the same, i.e. 1 flop. This is not exactly true, since multiplication includes several additions and division includes several multiplications when actually executed by a computer. However, we are looking for an estimate here, so it is reasonable to assume that on average, all operations count in the same manner.
Here is an example (just for illustration):
- for i = 0 to P
- for n = 1 to N (number of elements in array)
- B(n) = a(n)*a(n-1) - 2*c(n) + 3
- B(n) = a(n)*a(n-1) - 2*c(n) + 3
- next n
- for n = 1 to N (number of elements in array)
- next i
For each n there are 2 multiplications, 1 subtraction, and 1 addition resulting in 4 operations. This loop is executed N times, so there are 4N operations. This is the the order of the algorithm. In this example, its is O(4N) or simply O(N) (constants do not count).
For all iterations, there are 4N(P+1) operations. (remember, when starting the loop from 0 to P, there are P+1 steps).
Codes and Coding
Which code should I use?
This question is asked frequently (in one form or another) in the CFD-Online Forums, and there is no easy answer. There are many commercial and noncommercial codes out there, so researching the applicability of various codes is probably worth the effort. Links to lists of CFD codes are available in the CFD-Online Resources list.
I'm writing my own code. Which programming language should I use?
This question, like the previous question, is common and not easy to answer (at least without igniting long discussions - search in the Main Forum archive for examples). Traditionally, the language of choice was Fortran, but C++ and other more recently developed languages are becoming more common. Criticisms of non-Fortran languages usually are based upon performance of the end-result executable, but this sort of criticism has less power as computers become faster.
Meshing
What are the advantages/disadvantages of structural and unstructured Mesh?
What are the type of Mesh used for Boundary layer?